
[算法基础] DFS vs BFS
DFS(Depth First Search 深度优先搜索)和 BFS(Breadth First Search 广度优先搜索)是遍历图或树常用的两种方式。
BFS广度优先的遍历顺序如图:
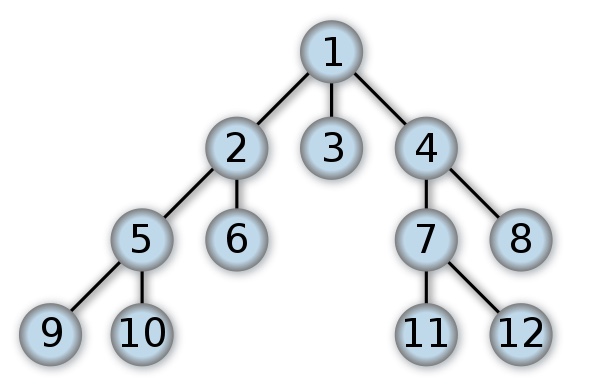
BFS按照图或树的层级level,一层层地访问。优先访问和当前节点在同一层的兄弟节点,等兄弟节点都访问完成,再考虑下一层的子节点们。
DFS深度优先的遍历顺序如图:
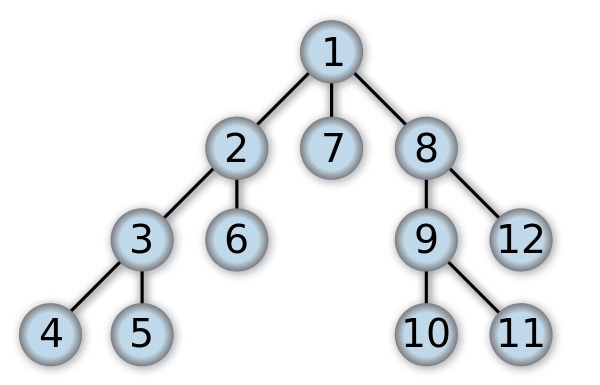
DFS是优先访问当前节点的子节点,当所有子节点遍历完成后,再返回当前层级访问下一个兄弟节点。树的DFS有很多种,包括pre-order, in-order and post-order,图中选择的是pre-order traverse。
time/space complexity - DFS vs BFS
在图或树的深度和广度随机的情况下DFS和BFS的时间和空间复杂度是差不多的。
对于有N个节点的树:
DFS & BFS的时间都是O(N)
对于有V个节点和E条边的图:
DFS & BFS的时间都是O(V + E)
对于深度是D的树或者图:
DFS遍历的space是O(D)
对于广度是L的树或者图:
BFS遍历的space是O(L)
因此当 D > L 时,为节省空间可以选择 BFS,反之 L > D 则使用DFS。
Implementation
BFS 需要自己写一个Queue来记录访问过的节点的顺序。
DFS 通常用递归实现,由于记录节点的递归栈由系统代为处理,代码实现很简洁。缺点是栈空间很宝贵,在现实工作中数据量巨大的情况下递归几乎不可行。这时就需要自己在内存中实现一个栈,这样一来和需要用到Queue的BFS相比实现起来就没有差别了。
不过对于算法面试来说,没有数据量的限制,通常选择代码少的DFS。
class Node {
int label;
List<Node> children;
}
input
Node root //连通图或树的起点
output
//print labels of nodes
BFS:
public void traverseBFS(Node root) {
if(root == null) return;
List<Node> queue = new LinkedList<>();
queue.add(root);
while(!queue.isEmpty()) {
Node current = queue.poll();
for(Node child: current.children) queue.add(child);
System.out.print(current.label + “ ”);
}
}
DFS:
public void traverseDFS(Node root) {
if(root == null) return;
System.out.print(root.label + “ “);
for(Node child: root.children) traverseDFS(child);
}
Get one-to-one training from Google Facebook engineers
Top-notch Professionals
Learn from Facebook and Google senior engineers interviewed 100+ candidates.
Most recent interview questions and system design topics gathered from aonecode alumnus.
One-to-one online classes. Get feedbacks from real interviewers.
Customized Private Class
Already a coding expert? - Advance straight to hard interview topics of your interest.
New to the ground? - Develop basic coding skills with your own designated mentor.
Days before interview? - Focus on most important problems in target company question bank.


